7M ⚡️ Cập Nhật Tỷ Số Bóng Đá Trực Tiếp & Kết Quả KQBD 7MCN Mới Nhất
7M là nền tảng cung cấp dữ liệu bóng đá hàng đầu, nơi hội tụ của ba giá trị cốt lõi: Tốc độ cực nhanh, độ chính xác tuyệt đối và kho dữ liệu khổng lồ. Bài viết này sẽ hướng dẫn bạn cách khai thác tối đa các công cụ quyền năng tại 7M để không bỏ lỡ bất kỳ khoảnh khắc nghẹt thở nào trên sân cỏ.
7M là gì? Tổng quan về nền tảng dữ liệu bóng đá hàng đầu
Trước mắt chúng ta nên nắm được trang thể thao 7M là một trong tổng hợp dữ liệu bóng đá trực tuyến dạng livescore 2 in 1 theo thời gian thực suốt trận đấu, trước và sau trận đấu. Tổng hợp các dữ liệu bóng đá, tin tức, kèo bóng đá, các loại kèo nhà cái, các tỷ lệ, nhận định soi kèo được cập nhật tại trang 7MCN.
- Nguồn gốc: 7M ra đời từ những ngày đầu của kỷ nguyên số, bắt nguồn với mục tiêu đơn giản là cung cấp tỉ số trực tuyến. Qua nhiều năm, nó đã phát triển thành một “siêu ứng dụng” về dữ liệu thể thao.
- Sứ mệnh: Cung cấp giải pháp tra cứu thông tin bóng đá toàn diện, giúp người hâm mộ và các nhà đầu tư đưa ra những quyết định chính xác dựa trên con số thực tế.
- Độ phủ: Không chỉ giới hạn ở các giải đấu lớn, 7M bao phủ hơn 1.000 giải đấu trên toàn thế giới, từ World Cup, Champions League cho đến các giải bóng đá cỏ tại khu vực Nam Mỹ hay Đông Nam Á.
Những điểm đột phá trong tính năng tại 7m cn livescore 2 in 1
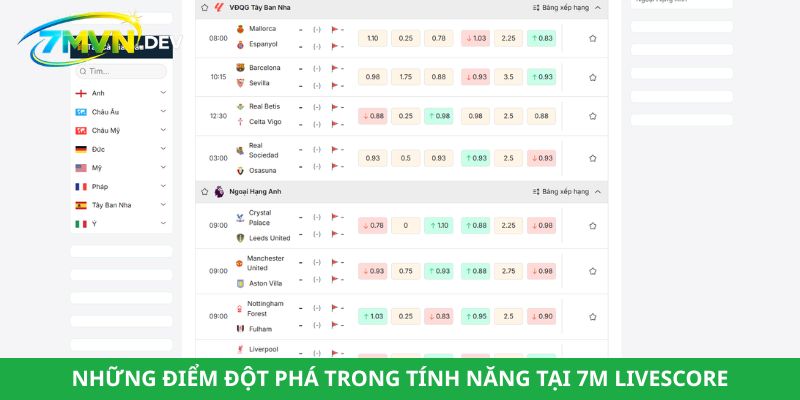
Livescore tính năng đột phát tại 7M Sport
Để duy trì vị thế dẫn đầu thị trường hiện nay, hệ thống đã không ngừng cải tiến thuật toán và hạ tầng băng thông. Những tính năng được phát triển tại đây đều dựa trên nhu cầu thực tế của người dùng, đảm bảo tính tiện lợi và độ trễ thấp nhất.
7M CN Livescore 2 in 1 – cập nhật tỉ số trực tuyến từng giây
Khả năng truyền tải dữ liệu theo thời gian thực chính là điểm cốt lõi làm nên giá trị của nền tảng. Khi một bàn thắng được ghi ở một giải đấu xa xôi tại Nam Mỹ hay các giải trẻ tại châu Âu, hệ thống 7MCN Livescore 2 in 1 chỉ mất vài giây để hiển thị thông số lên màn hình của người dùng.
Tốc độ này gần như tương đương với tín hiệu truyền hình trực tiếp, thậm chí nhanh hơn một số nền tảng phát sóng hàng đầu hiện nay. Điểm đặc biệt là bên cạnh tỉ số, các thông tin như người ghi bàn, thời điểm có bàn thắng, thẻ phạt hay các tình huống VAR can thiệp cũng được mô tả chi tiết.
Bảng kèo 7M CN Ma Cao – tỷ lệ kèo nhà cái chính xác nhất
Ngoài việc theo dõi kết quả, khả năng phân tích thị trường thông qua bảng kèo 7M cũng là yếu tố quan trọng thu hút người dùng. Hệ thống tự động tổng hợp dữ liệu từ hàng trăm nguồn uy tín để đưa ra những con số sát thực nhất với biến động của thị trường.
- Tổng hợp kèo Châu Á (Handicap), Châu Âu (1×2), Tài Xỉu (O/U): Các loại hình kèo phổ biến nhất luôn được hiển thị ở vị trí dễ quan sát. Người xem có thể thấy rõ mức chấp, tỉ lệ ăn tiền và các thay đổi của nhà cái theo từng giai đoạn của trận đấu. Việc trình bày khoa học giúp người dùng tiết kiệm thời gian đáng kể trong việc tra cứu.
- Biến động tỷ lệ kèo (Odds) liên tục theo thời gian thực: Thị trường bóng đá luôn biến chuyển theo thông tin lực lượng hoặc tâm lý đám đông. Tại 7M, mọi sự thay đổi dù là nhỏ nhất về Odds đều được cập nhật ngay lập tức. Những biểu đồ màu sắc xanh đỏ minh họa cho việc tăng giảm tỉ lệ giúp người xem dễ dàng nắm bắt xu hướng của thị trường.
- Hỗ trợ so sánh kèo giữa các nhà cái uy tín để người chơi dễ lựa chọn: Thay vì phải mở nhiều tab trình duyệt khác nhau, bạn có thể xem bảng so sánh trực quan giữa các đơn vị cung cấp kèo. Điều này giúp tối ưu hóa giá trị thông tin và mang lại cái nhìn khách quan nhất cho những ai đang tìm kiếm sự chuẩn xác trong việc dự đoán kết quả.
Thống kê dữ liệu (Data) & lịch sử đối đầu
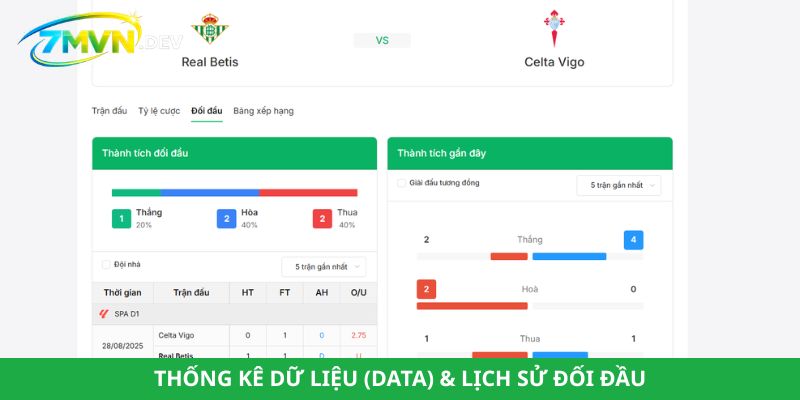
Thống kê dữ liệu trận đấu diễn ra chi tiết
Sức mạnh thực sự của một website dữ liệu nằm ở kho lưu trữ lịch sử và khả năng phân tích con số. Đây là nơi mà những người yêu thích sự logic có thể tìm thấy mọi thông tin cần thiết để phục vụ cho các bài viết đánh giá hoặc nhận định chuyên sâu.
- Phân tích phong độ 5-10 trận gần nhất của hai đội: Không chỉ xem thắng hay thua, hệ thống còn thống kê chi tiết đối thủ trong các trận đó là ai, sức mạnh ra sao. Qua đó, người dùng tại 7M có thể đánh giá được đội bóng đang có chuỗi trận ổn định hay chỉ là những chiến thắng may mắn trước các đối thủ yếu.
- Tỉ lệ thắng kèo, hiệu số bàn thắng bại, danh sách cầu thủ chấn thương/treo giò: Thông tin về nhân sự luôn đóng vai trò then chốt. Sự vắng mặt của một cầu thủ quan trọng vì chấn thương hoặc án treo giò hoàn toàn có thể khiến thế trận thay đổi đáng kể. Các dữ liệu này được đội ngũ biên tập viên kiểm chứng và cập nhật liên tục từ các nguồn tin nội bộ uy tín.
- Chỉ số phạt góc, thẻ vàng, tỉ lệ kiểm soát bóng chuyên sâu: Những chỉ số này ngày càng được người hâm mộ quan tâm. Việc biết được một đội bóng có lối chơi thiên về tấn công biên hay phòng ngự phản công thông qua số lượng phạt góc và thẻ phạt giúp người xem có cái nhìn đa chiều và thấu đáo hơn về chiến thuật của các huấn luyện viên.
Nhận định, dự đoán từ chuyên gia 7M
Đứng sau những con số là đội ngũ chuyên gia giàu kinh nghiệm. Họ là những người có khả năng đọc trận đấu và phân tích những biến số không thể nhìn thấy chỉ qua các bảng thống kê. Các bài viết nhận định tại đây không chỉ dựa trên cảm tính mà là sự kết hợp nhuần nhuyễn giữa dữ liệu toán học và kinh nghiệm thực chiến trên sân cỏ.
Mỗi nhận định đều đi kèm với các lập luận chặt chẽ về tình hình đội hình, tâm lý thi đấu và lịch sử chạm trán giữa hai câu lạc bộ. Người dùng tìm đến chuyên mục này của 7M.CN như một cách để kiểm chứng lại dự đoán cá nhân hoặc tìm kiếm những góc nhìn mới mẻ về các trận đấu tâm điểm.
Tại sao 7M luôn là lựa chọn số 1 của người hâm mộ?
Tại sao 7M luôn là lựa chọn số 1 của người hâm mộ?
Như đã nói hiện nay có rất nhiều trang web livescore, nhưng sự trung thành của người dùng đối với chúng tôi bắt nguồn từ sự chỉn chu trong từng chi tiết nhỏ nhất của hệ thống.
Tốc độ tải trang nhanh
Tốc độ tải trang luôn được ưu tiên hàng đầu trong các đợt nâng cấp định kỳ. Đội ngũ kỹ thuật hiểu rằng trong những khoảnh khắc quyết định, việc trang web bị lag hay xoay vòng sẽ gây ra sự ức chế rất lớn.
Chính vì thế, hạ tầng của 7MVN được tối ưu hóa để tương thích với mọi loại trình duyệt và chất lượng mạng, từ 4G yếu cho đến cáp quang tốc độ cao. Dữ liệu được nén tối đa nhưng vẫn đảm bảo độ sắc nét và đầy đủ, giúp trang web luôn vận hành mượt mà ngay cả khi có hàng triệu lượt truy cập cùng lúc vào các đêm thi đấu Champions League.
Giao diện trực quan
Cách bố trí các mục lục, thanh tìm kiếm và bộ lọc giải đấu được sắp xếp theo thói quen sử dụng của người Việt. Bạn có thể dễ dàng chuyển đổi giữa việc xem tỉ số của các giải với nhau chỉ bằng một cú chạm. Màu sắc trang nhã, không sử dụng quá nhiều banner quảng cáo gây nhiễu giúp người dùng tập trung hoàn toàn vào các con số chuyên môn.
Tính bảo mật cao

Tính bảo mật và an toàn thông tin là cam kết không thay đổi của hệ thống. Việc bảo vệ thiết bị của người dùng khỏi các phần mềm độc hại là vô cùng quan trọng. Truy cập vào 7M, bạn có thể hoàn toàn yên tâm vì hệ thống luôn được quét và bảo vệ bởi các tiêu chuẩn an ninh mạng khắt khe nhất. Không có hiện tượng tự động chuyển hướng trang hay yêu cầu cung cấp thông tin cá nhân trái phép, tạo ra một môi trường theo dõi thể thao lành mạnh và an toàn.
App di động 7M CN mượt mà
Với sự dịch chuyển của thói quen sử dụng từ máy tính sang điện thoại, ứng dụng được phát triển riêng biệt cho cả iOS và Android đã mang lại sự linh hoạt tuyệt đối.
App được tối ưu mượt mà và tiết kiệm dung lượng data, nhưng vẫn cung cấp đầy đủ các tính năng thông báo bàn thắng, xem lịch thi đấu và phân tích chuyên sâu. Chỉ cần một chiếc smartphone, bạn có thể nắm giữ toàn bộ thông tin bóng đá toàn cầu tại bất cứ đâu.
Hướng dẫn cách xem tỉ số và soi kèo tại 7M nhanh nhất
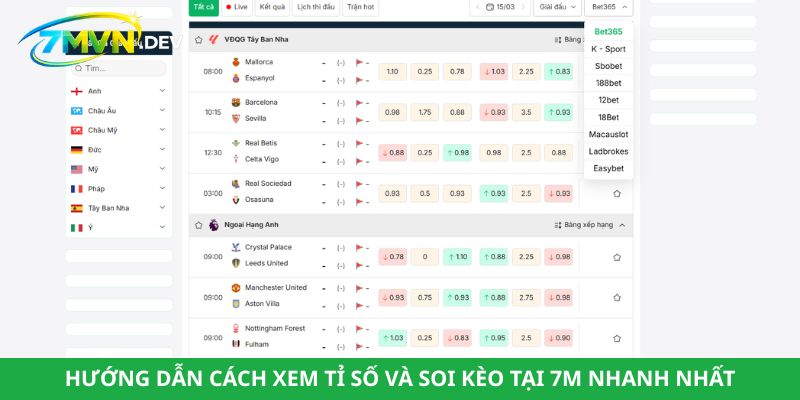
Hướng dẫn cách xem tỉ số và soi kèo tại 7M nhanh nhất
Để có thể sử dụng dịch vụ bóng đá mà hệ thống cung cấp, người dùng nên thực hiện theo các bước trình tự dưới đây.
Bước 1: Truy cập và thiết lập giao diện ưu tiên
Đầu tiên, người dùng cần truy cập vào trang chủ chính thức của hệ thống. Tại đây, một danh sách dài các trận đấu từ khắp nơi trên thế giới sẽ hiện ra. Tuy nhiên, để tránh bị loãng thông tin, bạn nên sử dụng bộ lọc “Chọn giải” nằm ở thanh menu ngang.
Bạn có thể tích chọn vào các giải đấu lớn như Ngoại hạng Anh, Champions League hay các giải đấu nội địa để hệ thống 7M Sport lọc riêng những trận cầu đó lên vị trí ưu tiên. Việc thiết lập này giúp màn hình hiển thị gọn gàng, tập trung đúng vào nhu cầu theo dõi của bạn.
Bước 2: Kích hoạt tính năng thông báo và âm thanh trực tiếp
Trong bóng đá, chỉ cần một giây lơ là là bạn đã có thể bỏ lỡ một bàn thắng đẹp mắt. Để khắc phục điều này, tại giao diện bảng điểm của 7M, bạn hãy tìm biểu tượng chiếc loa nhỏ.
Khi nhấn kích hoạt, hệ thống sẽ tự động phát âm thanh mỗi khi có rung lưới, thẻ đỏ hoặc tiếng còi kết thúc trận đấu. Đây là bước cực kỳ quan trọng cho những người muốn cập nhật kết quả tại 7M trong khi đang xử lý các công việc khác trên máy tính mà không cần phải nhìn vào màn hình liên tục.
Bước 3: Phân tích thông số chuyên sâu và biến động kèo
Sau khi đã chọn được trận đấu ưng ý, bạn hãy click trực tiếp vào dòng tỉ số để mở ra cửa sổ dữ liệu chi tiết. Tại đây, hệ thống 7M cung cấp cho bạn các tab riêng biệt. Bạn nên bắt đầu từ tab “Phân tích” để xem lịch sử đối đầu và phong độ gần đây, sau đó chuyển sang tab “Kèo” để theo dõi sự dịch chuyển của Odds.
Việc quan sát các con số tại 7M từ thời điểm sớm cho đến sát giờ thi đấu sẽ giúp người xem nhận diện được những thay đổi bất thường trong đánh giá của giới chuyên môn, từ đó đưa ra quyết định bắt kèo chuẩn xác nhất.
Một số lưu ý khi sử dụng dữ liệu từ 7M
Dữ liệu tại 7M là những con số khách quan, nhưng bóng đá luôn chứa đựng những biến số vô hình như sai lầm của trọng tài, điều kiện thời tiết khắc nghiệt hay những khoảnh khắc xuất thần của một cá nhân. Do đó, hãy coi thông tin từ 7M là cơ sở khoa học để tham khảo chứ không nên tuyệt đối hóa mọi dự đoán.
Một lưu ý khác là về vấn đề múi giờ. Dù hệ thống thường tự động nhận diện múi giờ theo vị trí địa lý của bạn, nhưng đôi khi trong các trường hợp sử dụng VPN hoặc phần mềm đổi IP, lịch thi đấu có thể bị lệch.
Hãy luôn kiểm tra cài đặt giờ giấc trên trang để chắc chắn bạn không bị nhầm lẫn giữa giờ Việt Nam và giờ quốc tế. Đồng thời, việc thường xuyên làm mới trang web hoặc đảm bảo ứng dụng luôn ở phiên bản mới nhất sẽ giúp dữ liệu được cập nhật trơn tru nhất.
Câu hỏi thường gặp (FAQ) về 7M

Câu hỏi thường gặp (FAQ) về 7M
Để giúp người dùng hiểu rõ hơn về cách vận hành của hệ thống, chúng tôi đã tổng hợp các thắc mắc phổ biến nhất và đưa ra lời giải đáp ngắn gọn, súc tích.
7M có cập nhật kết quả bóng đá V-League không?
Có. Hệ thống cung cấp thông tin chi tiết về tất cả các vòng đấu của V-League, Cup Quốc gia và cả giải Hạng Nhất Việt Nam. Mọi diễn biến từ sân vận động Mỹ Đình cho đến Thống Nhất đều được đội ngũ cộng tác viên cập nhật nhanh chóng, phục vụ nhu cầu theo dõi bóng đá nội của đông đảo người hâm mộ trong nước. Xem chi tiết các kết quả bóng đá 7M tại đây: https://redhat-gitops-patterns.io/ket-qua-bong-da/
Làm thế nào để bật thông báo tiếng khi có bàn thắng trên 7M?
Bạn chỉ cần quan sát biểu tượng hình cái loa nhỏ ở thanh công cụ phía trên bảng tỉ số. Khi nhấn vào đó, biểu tượng sẽ chuyển sang trạng thái kích hoạt. Từ lúc này, mỗi khi có bàn thắng, thẻ đỏ hoặc kết thúc hiệp đấu, hệ thống sẽ phát ra âm thanh thông báo.
Xem tỉ số trên 7M có mất phí không?
Người dùng không phải trả bất kỳ một khoản phí nào khi truy cập và sử dụng các dịch vụ tại đây. Toàn bộ kho dữ liệu khổng lồ từ kết quả trực tuyến, lịch thi đấu đến các bài phân tích chuyên gia đều được cung cấp miễn phí 100%.
7M có xem được trực tiếp bóng đá (Livestream) không?
Hiện tại, đơn vị này tập trung chuyên sâu vào mảng dữ liệu số và thống kê trực tuyến chứ không trực tiếp phát sóng hình ảnh video. Tuy nhiên, tính năng mô phỏng trận đấu bằng đồ họa 2D tại 7M lại vô cùng xuất sắc. Bạn có thể thấy rõ hướng tấn công của trái bóng, vị trí đá phạt và các tình huống nguy hiểm thông qua sơ đồ mô phỏng theo thời gian thực, mang lại trải nghiệm thú vị không kém gì xem livestream.
Tại sao 7M có nhiều tên gọi khác nhau?
Hiện tại 7M là trang dữ liệu thể thao, bảng kèo, soi kèo nhanh chuẩn xác nhất. Cho nên việc trang thể thao 7M có nhiều tên gọi khác nhau như: 7M Sport, 7MCN, 7M.CN, 7M VN là do người dùng đặt và tìm kiếm trên internet.
Dữ liệu trên 7M có độ trễ (delay) so với thực tế bao lâu?
Độ trễ là một trong những niềm tự hào của hệ thống. Thông thường, thông tin chỉ chậm hơn diễn biến thực tế khoảng vài giây. Điều này đạt được nhờ vào mạng lưới máy chủ dày đặc và các giao thức truyền tải dữ liệu siêu tốc. Người dùng có thể yên tâm rằng mình đang được tiếp cận với những thông tin bóng đá nóng hổi và cập nhật nhất trên thị trường hiện nay.
Lời kết
Có thể thấy 7M đã thực hiện rất tốt sứ mệnh kết nối người hâm mộ với nhịp đập của sân cỏ thế giới. Nhờ ứng dụng công nghệ hiện đại cùng khả năng nắm bắt tâm lý người dùng, thương hiệu đã tạo nên dấu ấn riêng khó thay thế.